There may be times when you want to directly connect to a data source that Reveal might not support yet out of the box. For instance, you may have your own custom database. To accommodate this need, we support in-memory as a data source. You may also want to use this option if you need to use data already in memory as part of your application state, such as the result of a report requested by a user.
In-memory data source also offers other benefits such as retrieval speed as it is much faster to access data in memory than on a disk drive.
In this blog we’ll step through how to use this feature.
Defining a Data Schema
We recommend you define a data file with a schema that matches your in-memory data. Data files can be, for example, a CSV or Excel file, and a schema is basically a list of fields and the data type for each field. In the example below you’ll find details about how to create a data file with a given schema, and then use data in memory instead of getting information from a database.
In the following example, we’ll use in-memory data with the list of employees in the company in order to embed a dashboard showing HR metrics in your HR system. And instead of getting the list of employees from your database, we’ll use the data in memory.
Preparing the Data File and Sample Dashboard
Use the following steps based on a simplified Employee that only has a few properties:
- EmployeeID: string
- Fullname: string
- Wage: numeric
First create the CSV file with the same schema:

- Upload the file to your preferred file sharing system, like Dropbox or Google Drive
- Create a dashboard using the dummy data. Please note that you are going to provide the real production data later in your application
- Export the dashboard (Dashboard Menu → Export → Dashboard) and save as a .rdash file.
Visualizing the Dashboard and Returning the Actual Data
Now you need to visualize the dashboard using your own data instead of the dummy one.
Implement IRVDataSourceProvider and return it as the DataSourceProvider property in IRevealSdkContext, as described in Replacing Data Sources.
Then, in the implementation for the method ChangeVisualizationDataSourceItemAsync, you need to add a code similar to this one:

This way you basically replace all references to CSV files in the dashboard with the in-memory data source identified by “employees”. This identification will be used later when returning the data.
Implement the method that will return the actual data, to do that implement IRVDataProvider as shown below:

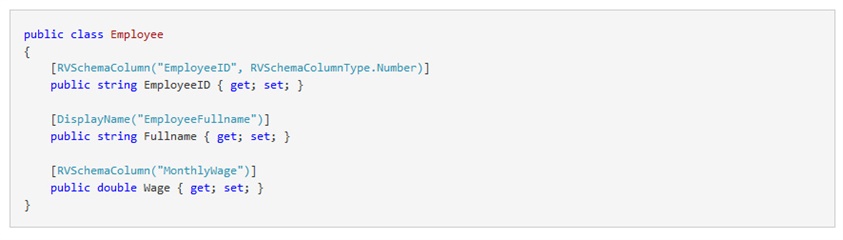
Please note that the properties in the Employee class are named exactly as the columns in the CSV file, and the data type is also the same. In case you want to alter the field name, field label and/or data type of any of the properties you can use attributes in the class declaration:
- RVSchemaColumn attribute can be used to alter the field name and/or data type.
- DisplayName attribute can be used to alter the field label
In addition, to implement IRVDataProvider you need to modify your implementation of IRevealSdkContext.DataProvider to return it:

To learn more about Reveal or trial the SDK if you haven’t yet done so, request a demo.